https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/
1. Convert an Audio File into Text (not live, not automatically save it into a text file)
Whisper AI is an advanced automatic speech recognition (ASR) model developed by OpenAI that can transcribe audio into text with impressive accuracy and supports multiple languages. While Whisper AI is primarily designed for batch processing, it can be configured for real-time speech-to-text transcription on Linux.
In this guide, we will go through the step-by-step process of installing, configuring, and running Whisper AI for live transcription on a Linux system.
What is Whisper AI?
Whisper AI is an open-source speech recognition model trained on a vast dataset of audio recordings and it is based on a deep-learning architecture that enables it to:
- Transcribe speech in multiple languages.
- Handle accents and background noise efficiently.
- Perform translation of spoken language into English.
Since it is designed for high-accuracy transcription, it is widely used in:
- Live transcription services (e.g., for accessibility).
- Voice assistants and automation.
- Transcribing recorded audio files.
By default, Whisper AI is not optimized for real-time processing. However, with some additional tools, it can process live audio streams for immediate transcription.
Whisper AI System Requirements
Before running Whisper AI on Linux, ensure your system meets the following requirements:
Hardware Requirements:
- CPU: A multi-core processor (Intel/AMD).
- RAM: At least 8GB (16GB or more is recommended).
- GPU: NVIDIA GPU with CUDA (optional but speeds up processing significantly).
- Storage: Minimum 10GB of free disk space for models and dependencies.
Software Requirements:
- A Linux distribution such as Ubuntu, Debian, Arch, Fedora, etc.
- Python version 3.8 or later.
- Pip package manager for installing Python packages.
- FFmpeg for handling audio files and streams.
Step 1: Installing Required Dependencies
Before installing Whisper AI, update your package list and upgrade existing packages.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Next, you need to install Python 3.8 or higher and Pip package manager as shown.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Lastly, you need to install FFmpeg, which is a multimedia framework used to process audio and video files.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Step 2: Install Whisper AI in Linux
Once the required dependencies are installed, you can proceed to install Whisper AI in a virtual environment that allows you to install Python packages without affecting system packages.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
Once the installation is complete, check if Whisper AI was installed correctly by running.
whisper --help
This should display a help menu with available commands and options, which means Whisper AI is installed and ready to use.
Step 3: Running Whisper AI in Linux
Once Whisper AI is installed, you can start transcribing audio files using different commands.
Transcribing an Audio File
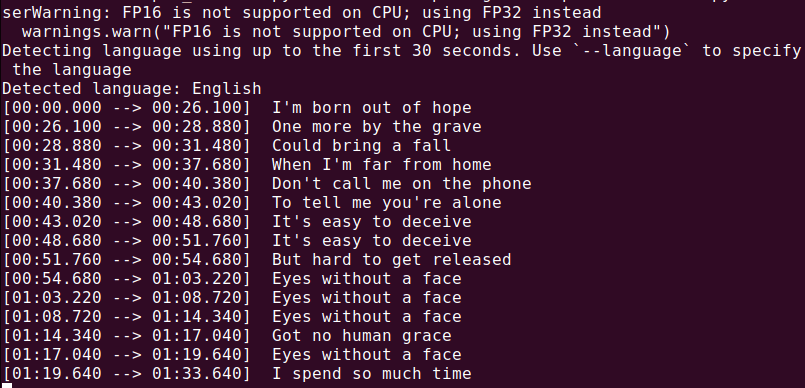
To transcribe an audio file (audio.mp3), run:
whisper audio.mp3
Whisper will process the file and generate a transcript in text format.
Auto-save text to Markdown / notes, please. Thank you!
------------------------------------------------------------------------------
You got it 👍
Below is a **NOT LIVE** but **clean, practical Whisper setup that automatically saves transcripts as well-formatted Markdown notes**. This works great for meetings, study notes, or voice journals.
I’ll give you:
1. 📁 Folder-based auto-transcription
2. 📝 Markdown formatting (title, timestamps, sections)
3. ⚙️ A reusable script you can customize
1️⃣ **Folder Structure (recommended)**
whisper_notes/
├── audio/ # put .wav / .mp3 here
├── notes/ # Markdown files auto-saved here
└── transcribe.py
Create it:
mkdir -p ~/whisper_notes/audio ~/whisper_notes/notes
cd ~/whisper_notes
2️⃣ **Install requirements (once)**
pip install openai-whisper torch
(You already installed Whisper, this just ensures dependencies.)
3️⃣ **Create the auto-Markdown script**
nano transcribe.py
Paste **this full script:**
import whisper
from pathlib import Path
from datetime import datetime
AUDIO_DIR = Path("audio")
NOTES_DIR = Path("notes")
MODEL_NAME = "medium" # change to small if CPU is slow
NOTES_DIR.mkdir(exist_ok=True)
model = whisper.load_model(MODEL_NAME)
def seconds_to_mmss(seconds):
m = int(seconds // 60)
s = int(seconds % 60)
return f"{m:02d}:{s:02d}"
for audio_file in AUDIO_DIR.iterdir():
if audio_file.suffix.lower() not in {".wav", ".mp3", ".m4a", ".flac"}:
continue
print(f"Transcribing: {audio_file.name}")
result = model.transcribe(audio_file, fp16=False)
title = audio_file.stem.replace("_", " ").title()
now = datetime.now().strftime("%Y-%m-%d %H:%M")
md_lines = [
f"# {title}",
"",
f"- **Date:** {now}",
f"- **Source:** `{audio_file.name}`",
"",
"## Transcript",
""
]
for seg in result["segments"]:
ts = seconds_to_mmss(seg["start"])
text = seg["text"].strip()
md_lines.append(f"- **[{ts}]** {text}")
md_file = NOTES_DIR / f"{audio_file.stem}.md"
md_file.write_text("\n".join(md_lines), encoding="utf-8")
print(f"Saved → {md_file}")
print("✅ All done.")
Save and exit.
4️⃣ **Use it (very simple)**
1️⃣ Put audio files into:
~/whisper_notes/audio/
2️⃣ Run:
python3 transcribe.py
3️⃣ Get Markdown notes in:
~/whisper_notes/notes/
5️⃣ Example Markdown Output
# Team Meeting Notes
- **Date:** 2025-01-21 14:30
- **Source:** `team_meeting.wav`
## Transcript
- **[00:00]** Good afternoon everyone, let's get started.
- **[00:32]** The first topic is system migration.
- **[02:15]** We expect completion by next Friday.
Perfect for:
- Obsidian
- VS Code
- GitHub
- Joplin
- Plain Markdown
6️⃣ **Optional Improvements (I can add these)**
✅ Auto-move processed audio
✅ One-file-per-day notes
✅ Headings instead of bullet timestamps
✅ Speaker labels (best-effort)
✅ Hotkey recording → auto-note
✅ Git auto-commit notes
✅ Summaries at top (AI-assisted)
Just tell me what you want next — this setup is a solid base 👌
I got the following error message -
'
Traceback (most recent call last):
File "/home/shermanchen/dev/whisperai/whisper_notes/transcribe.py", line 23, in <module>
result = model.transcribe(audio_file, fp16=False)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/shermanchen/dev/whisperai/whisper_env/lib/python3.12/site-packages/whisper/transcribe.py", line 139, in transcribe
mel = log_mel_spectrogram(audio, model.dims.n_mels, padding=N_SAMPLES)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/shermanchen/dev/whisperai/whisper_env/lib/python3.12/site-packages/whisper/audio.py", line 141, in log_mel_spectrogram
audio = torch.from_numpy(audio)
^^^^^^^^^^^^^^^^^^^^^^^
TypeError: expected np.ndarray (got PosixPath)
'
Great, thanks for pasting the full traceback — this is a **clear and easy fix** 👍
You’re actually **very close**.
✅ **What went wrong (exactly)**
This line caused it:
result = model.transcribe(audio_file, fp16=False)
`audio_file` is a Path object (`PosixPath`), but **Whisper expects either**:
- a string path (`str`)
- or a **NumPy array**
So Whisper tried to treat the `Path` like audio data → 💥 error.
✅ **The fix (one-line change)**
Convert the `Path` to a string.
**Edit your script:**
nano transcribe.py
**Change this line:**
result = model.transcribe(audio_file, fp16=False)
**To this:**
result = model.transcribe(str(audio_file), fp16=False)
Save and exit.
✅ **Run it again**
python3 transcribe.py
You should now see:
Transcribing: something.wav
Saved → notes/something.md
✅ All done.
🧠 **Why this happens (for future reference)**
- `pathlib.Path` is great for filesystem logic
- Whisper internally calls NumPy / Torch
- Those libraries **do not understand Path objects**
- Converting to `str()` is the correct and standard solution
This is a **very common Python + ML gotcha**, not your fault.
🔒 **Optional hardening (recommended)**
If you want to make the script more robust, you can add:
audio_path = audio_file.resolve()
result = model.transcribe(str(audio_path), fp16=False)
This avoids issues with symlinks or relative paths.
Next enhancements (I can implement any of these for you)
✔ Auto-move processed audio to audio/processed/
✔ Skip already-transcribed files
✔ Daily Markdown notes (append instead of overwrite)
✔ Add a summary section at the top
✔ Faster mode (--beam_size, --temperature)
✔ Hotkey recording → instant Markdown note
Just tell me what you want next — your setup is now solid ✅
This is the **best compromise** Whisper can do (because Whisper is not truly streaming).
How “Live” Whisper Actually Works (important)
------------------------------------------------------------------------------
Whisper **cannot transcribe word-by-word** like Vosk.
The correct way is:
🎤 Record short chunks (e.g. 5–10 seconds) → transcribe → append to Markdown → repeat
This gives:
- ✅ High accuracy
- ✅ Punctuation
- ✅ Continuous notes
- ❌ A few seconds delay (unavoidable)
✅ **Final Result**
- You speak continuously
- Every 5 seconds, Whisper transcribes
- Text is auto-appended to ONE Markdown note
- Timestamps included
- Stop anytime with Ctrl+C
**STEP 1 — Install dependencies (once)**
pip install openai-whisper sounddevice numpy
sudo apt install ffmpeg -y
**STEP 2 — Create live Markdown dictation script**
nano whisper_live_md.py
Paste **this full script**:
import whisper
import sounddevice as sd
import numpy as np
from datetime import datetime
from pathlib import Path
import queue
import time
MODEL_NAME = "small" # change to "medium" for higher accuracy
CHUNK_SECONDS = 5 # length per transcription chunk
SAMPLE_RATE = 16000
NOTES_DIR = Path("notes")
NOTES_DIR.mkdir(exist_ok=True)
note_file = NOTES_DIR / f"live_note_{datetime.now().strftime('%Y-%m-%d_%H-%M')}.md"
model = whisper.load_model(MODEL_NAME)
audio_q = queue.Queue()
def callback(indata, frames, time_info, status):
audio_q.put(indata.copy())
def seconds_to_mmss(seconds):
m = int(seconds // 60)
s = int(seconds % 60)
return f"{m:02d}:{s:02d}"
with note_file.open("w", encoding="utf-8") as f:
f.write(f"# Live Dictation Notes\n\n")
f.write(f"- **Started:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")
print("🎤 Live dictation started (Ctrl+C to stop)")
try:
with sd.InputStream(samplerate=SAMPLE_RATE, channels=1, callback=callback):
while True:
audio_chunks = []
start_time = time.time()
while time.time() - start_time < CHUNK_SECONDS:
audio_chunks.append(audio_q.get())
audio = np.concatenate(audio_chunks, axis=0).flatten()
result = model.transcribe(audio, fp16=False)
text = result["text"].strip()
if text:
timestamp = datetime.now().strftime("%H:%M:%S")
line = f"- **[{timestamp}]** {text}\n"
with note_file.open("a", encoding="utf-8") as f:
f.write(line)
print(text)
except KeyboardInterrupt:
print("\n🛑 Dictation stopped.")
print(f"📝 Saved to: {note_file}")
Save and exit.
**STEP 3 — Run it**
python3 whisper_live_md.py
Start speaking 🎤
Every ~5 seconds:
- Text appears in terminal
- Text is appended to Markdown
**Example Markdown Output (LIVE)**
# Live Dictation Notes
- **Started:** 2025-01-21 22:10:03
- **[22:10:08]** Today I am testing live dictation using Whisper.
- **[22:10:14]** The accuracy is much better than Vosk.
- **[22:10:20]** This will be saved automatically as markdown.
Perfect for:
- Obsidian
- VS Code
- Joplin
- GitHub notes
**Recommended Settings (Important)**
**CPU only (most laptops)**
MODEL_NAME = "small"
CHUNK_SECONDS = 5
**Higher accuracy**
MODEL_NAME = "medium"
CHUNK_SECONDS = 8
**Faster response**
MODEL_NAME = "base"
CHUNK_SECONDS = 3
(The End)
No comments:
Post a Comment